openmpi[0]-openmpi-img-parse
总览
Open MPI(Open 对称多处理器接口)是一个开源、高性能的 MPI(消息传递接口)实现。
核心概念解释:
- MPI (Message Passing Interface):MPI 不是一个编程语言,而是一个标准或规范。它定义了一套用于并行计算的函数库,允许不同的进程(通常运行在不同的处理器或计算节点上)通过显式地发送和接收消息来相互通信和协作。你可以把它想象成一套并行程序之间进行交流的“语言规则”。
- 并行计算:指将一个大的计算任务分解成许多小任务,这些小任务可以同时(并行地)在多个处理器上执行,以缩短完成整个任务所需的时间。
- 实现 (Implementation):MPI 本身只是一个标准,具体的编程库需要由不同的组织或公司去“实现”。Open MPI 就是众多 MPI 实现中的一个,其他著名的实现包括 MPICH、Intel MPI 等。
简而言之,Open MPI 就是一个让你能用 MPI 标准来编写并行程序,并在各种计算集群和多核处理器上高效运行这些程序的工具箱。
MPI的编程方式,是“一处代码,多处执行”。编写过多线程的人应该能够理解,就是同样的代码,不同的进程执行不同的路径
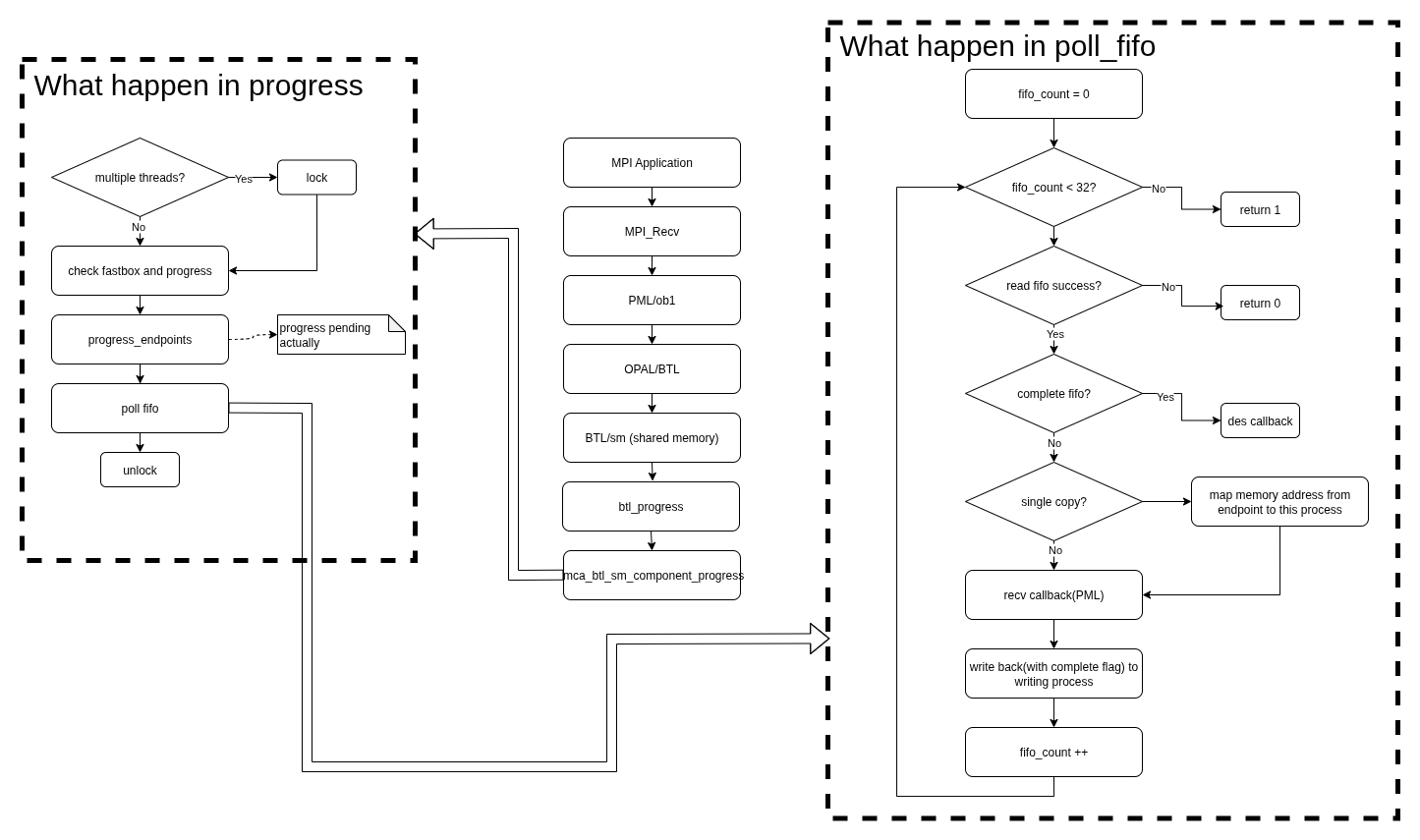
OpenMPI的架构图如下所示(old):
自上向下依次为:
- OMPI(Open MPI)
- 由MPI 标准定义的接口
- 暴露给上层的API接口,直接由应用程序调用
- ORTE(Open MPI Run-Time Environment) - 目前已经被PRRTE所取代,不过都是runtime的一层
- runtime system
- 加载,监控进程,杀死独立的进程
- 重定向stdin, stdout, stderr
- ORTE 进程管理方式:在简单的环境中,通过rsh或ssh 来launch 进程。而复杂环境(HPC专用)会有shceduler、resource manager等管理组件,面向多个用户进行公平的调度以及资源分配,ORTE支持多种管理环境,例如,orque/PBS Pro, SLURM, Oracle Grid Engine, and LSF.
- runtime system
- OPAL (Open, Portable Access Layer) (pronounced: o-pull): OPAL 是xOmpi的最底层,只作用于单个进程,负责不同环境的可移植性,包含了一些通用功能(例如链表、字符串操作、debug控制等等).
由于考虑到性能因素,Open MPI 有中“旁路”机制(bypass),ORTE以及OMPI层,可以绕过OPAL,直接与操作系统(甚至是硬件)进行交互.
例如OMPI会直接与网卡进行交互,从而达到最大的网络性能。这也就是为什么可以在架构图中看到,OMPI/ORTE与操作系统有一个旁路接口。
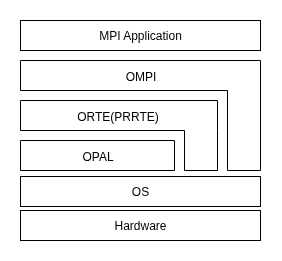
但是,openmpi自从v4.0开始,已经将ORTE移出openmpi框架。改为3rd-party并重命名为PRRTE.
最新架构图如下:
MCA Architecture
为了在 Open MPI 中使用类似功能但是不同实现,Open MPI 设计一套被称为Modular Component Architecture (MCA)的架构.
MCA架构的核心思想是,允许用户通过配置文件来选择使用哪些组件,而不需要修改源代码。
Open MPI 项目的架构图如下所示:
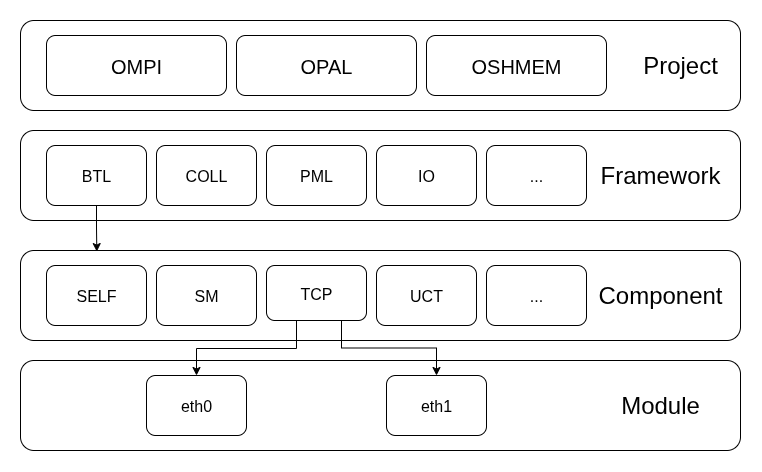
自顶向下依次为:
- Project: Project本质上是 Open MPI 代码库中最高抽象层的划分。但这里的Project可不是说的项目,而是指的Open MPI 代码库中主要的、顶层的代码部分
- OMPI
- OPAL
- OSHMEM: 提供对称堆分配器,支持不同类型的内存分配器;实现OpenSHMEM标准的通信原语,如put/get操作等;管理OpenSHMEM程序的初始化、进程管理和资源协调.
- … (maybe)
- Framework:
- BTL: 字节传输
- coll: 集合操作
- PML: 点对点传输
- …
- Component:
- self: 进程与他自身通信
- sm: 同一主机内的进程互相通信
- tcp: 通过tcp与其他主机内的进程通信
- …
- Module:
- eth0
- eth1
- …
BTL/self 实现: 同主机, 同进程, 不同线程通信
component
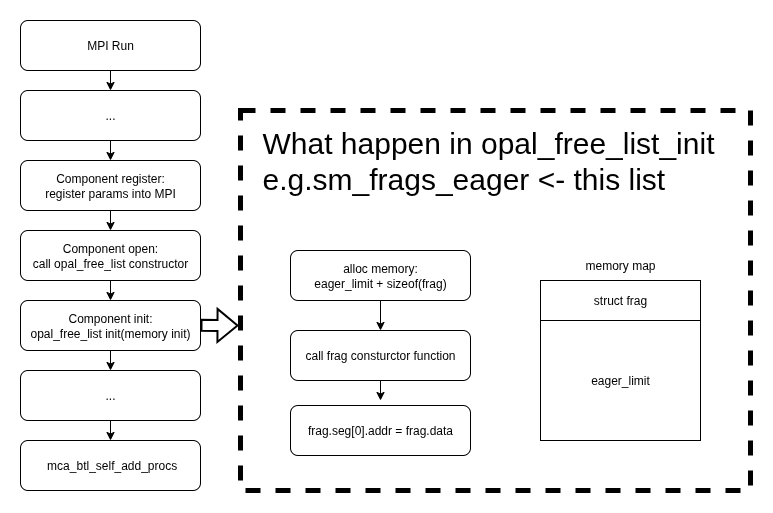
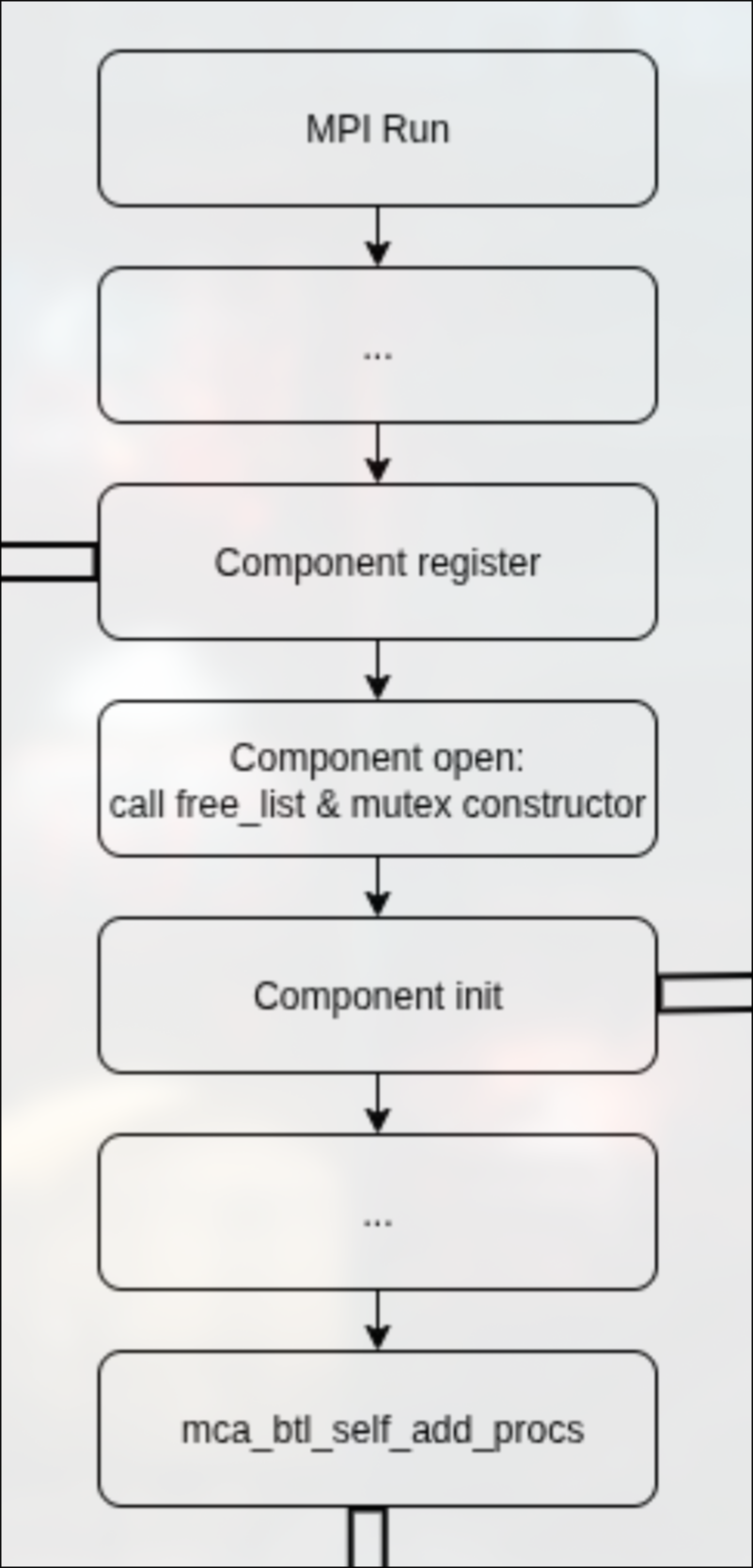
在btl的component实现中,最首先实现的是component的register和init函数。
register函数向mca架构注册了mca参数,init函数完成了opal_freelist的init工作。
这里提到了一个新的数据结构:opal_freelist, 这是Open MPI中OPAL层的一个核心内存管理组件,用于高效管理可重用对象的内存池。基于LIFO(后进先出)的内存池实现,主要作用是:
- 内存池管理:预分配固定大小的内存块,避免频繁的malloc/free操作
- 对象重用:支持对象的快速分配和回收
- 内存对齐:支持指定的内存对齐要求
- 动态扩展:当内存池耗尽时可以自动增长
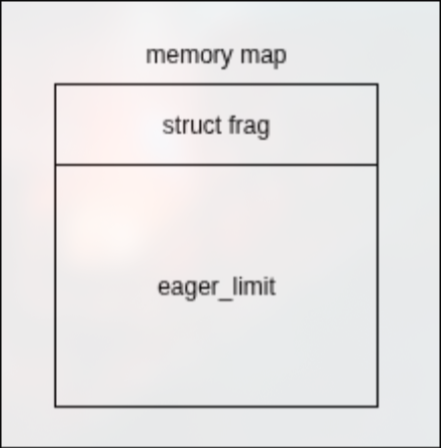
当opal_freelist初始化时,每一个opal_freelist_item的内存结构图如下所示:
在最后还调用了一个add_procs函数,这个函数是为了判断当前进程是否可以用该组件(self)进行通信,这也是openmpi自动选择组件的核心支撑之一。
self组件这里的实现很简单,就是判断想要与本进程通信的是不是本进程,如果是本进程则标记可以通信, 否则拒绝通信,让openmpi选择其他组件。
其实add_procs也是下一个标题的ops的一部分,不过搬到这里来讲是因为笔者认为它们都属于”init”初始化工作的一部分。
ops
在btl框架下的组件,需要实现btl框架要求的ops:
- add_procs: 已经在上面解释过
- del_procs: 删除process, 一般在finalize的时候调用,在self中直接返回成功
- finalize: 在self中直接返回成功
- alloc: 申请数据描述符函数(需要根据数据大小选择不同的数据描述符)
- free: 释放数据描述符函数
- prepare_src: 准备发送的数据
- send: 将数据实际发送
- sendi: prepare_src + send
- put: rdma put函数
- get: rdma get函数
send
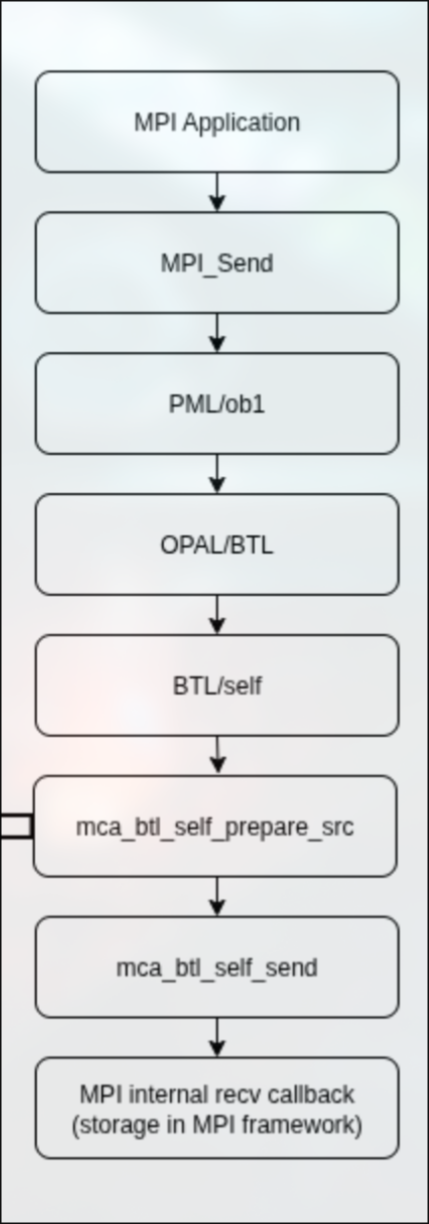
在send时,从MPI Application逐层调用,最终到达btl层。
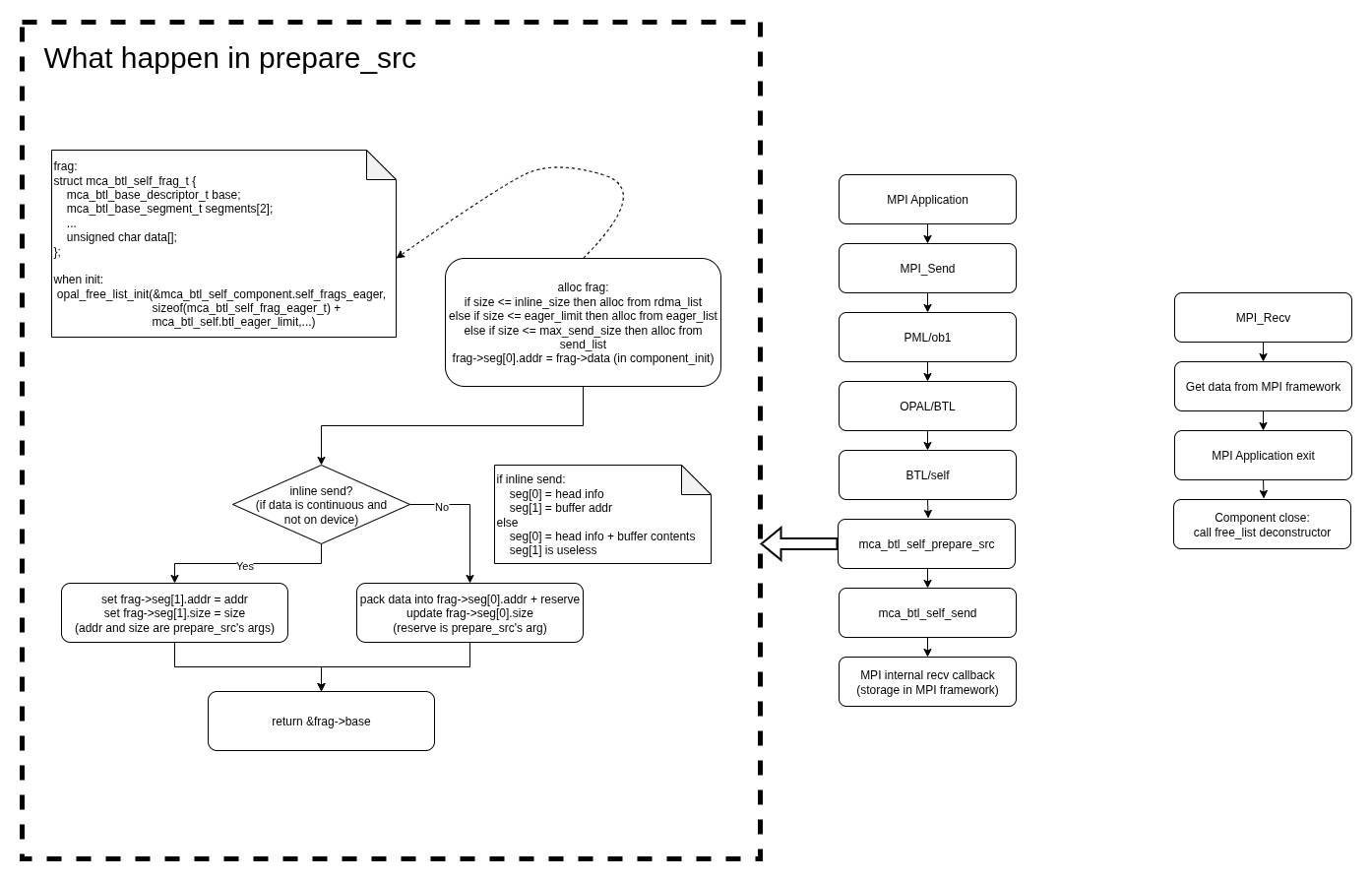
首先到达的并不会是send函数而是prepare_src函数,因为不是sendi这样的”原子操作”,所以数据准备发送是可以分开处理的。
在prepare_src函数中,先调用alloc函数申请数据描述符,然后判断是否为内联函数。
如果是内联函数,则直接将数据地址传递给数据描述符;否则通过iov将数据打包到数据描述符中的预申请buffer.
数据描述符的内存空间是在opal_freelist初始化的时候申请的,目的就是为了非内联发送的数据缓存。
之后在合适的时机调用到self的send函数。
self的send函数直接调用openmpi btl内部的接收回调函数,并将prepare_src时准备的数据描述符作为参数传递进去。
因为self是本进程与本进程通信,所有资源都是可以互相直接访问的,所以可以直接传递进去。
recv
在recv函数中,直接就可以从openmpi里面准备好的数据描述符拿到数据。
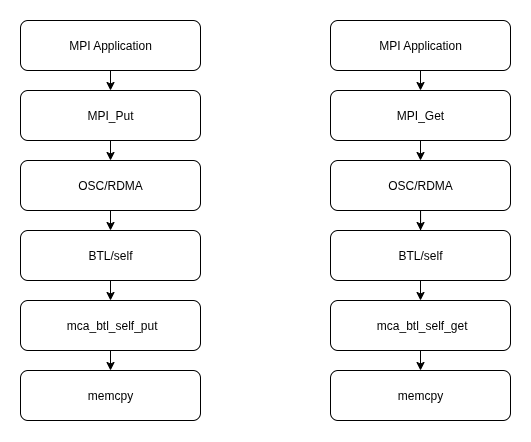
send & recv完整流程图如下:
rdma: put/get
在self进程中的rdma put/get操作,因为知道目标地址与源地址,所以就不需要那些麻烦的数据描述符。
而且是self进程间通信,所以rdma的put/get操作可以直接通过memcpy完成。
rdma put/get的流程图如下:
BTL/sm 实现: 同主机, 不同进程通信
component
sm的component流程与self类似,如下:
不过sm的component有许多细节需要解释。
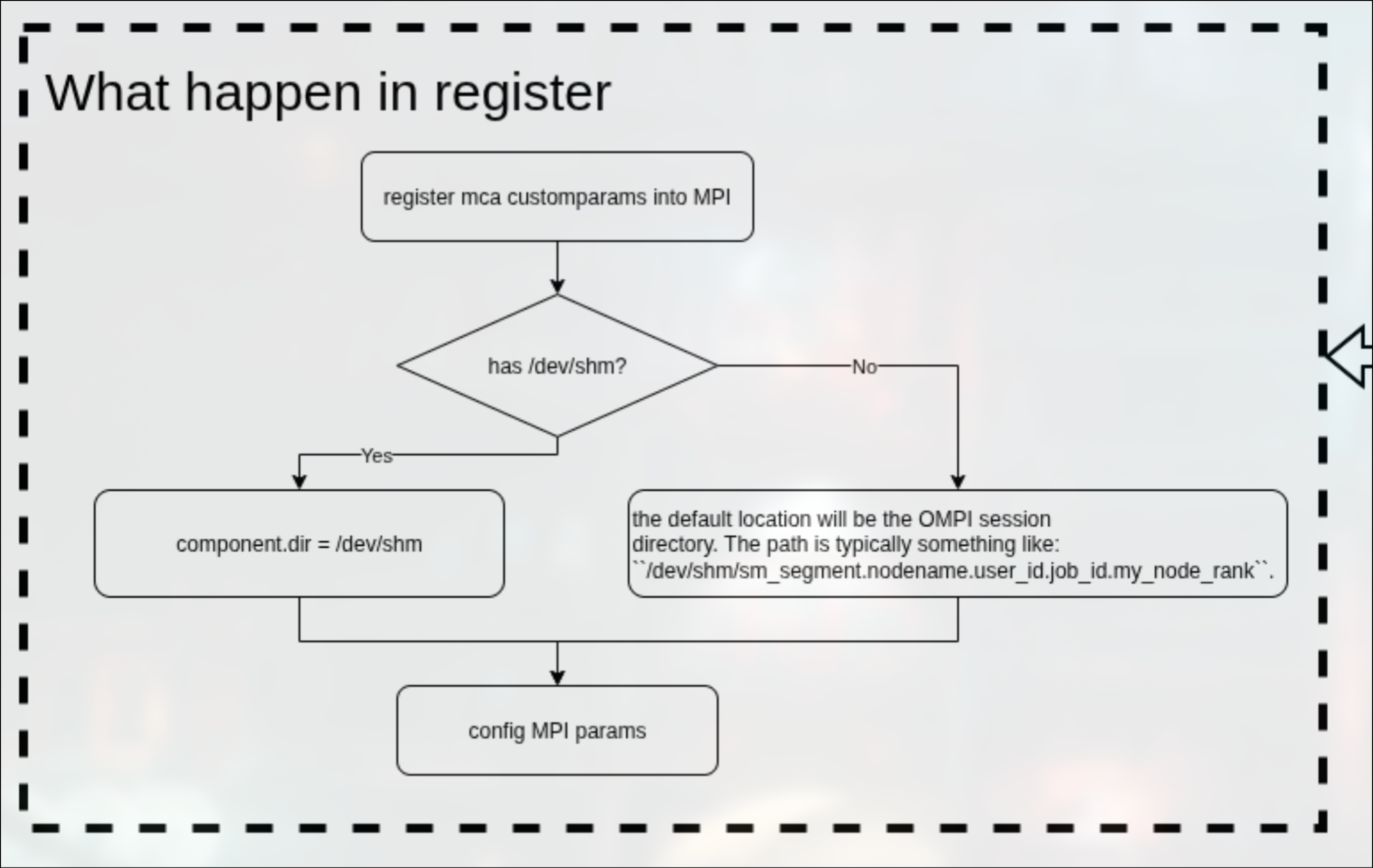
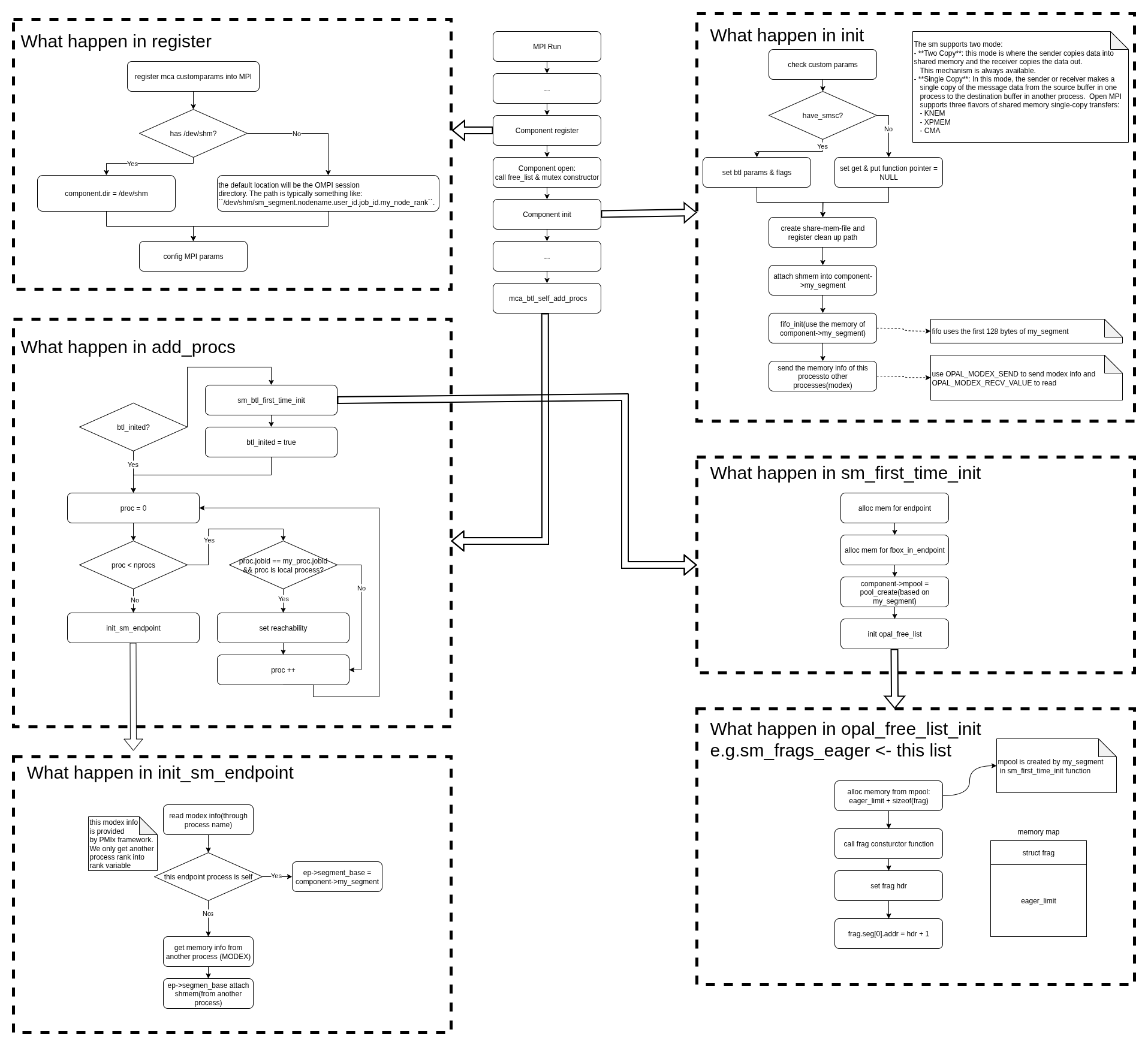
register
首先先注册自定义的mca参数到架构中,之后判断是否拥有/dev/shm目录。
如果有,则dir = /dev/shm,否则dir = OMPI session dir.
之后配置btl需要被传递的参数,这点与self一致。
具体框图:
init
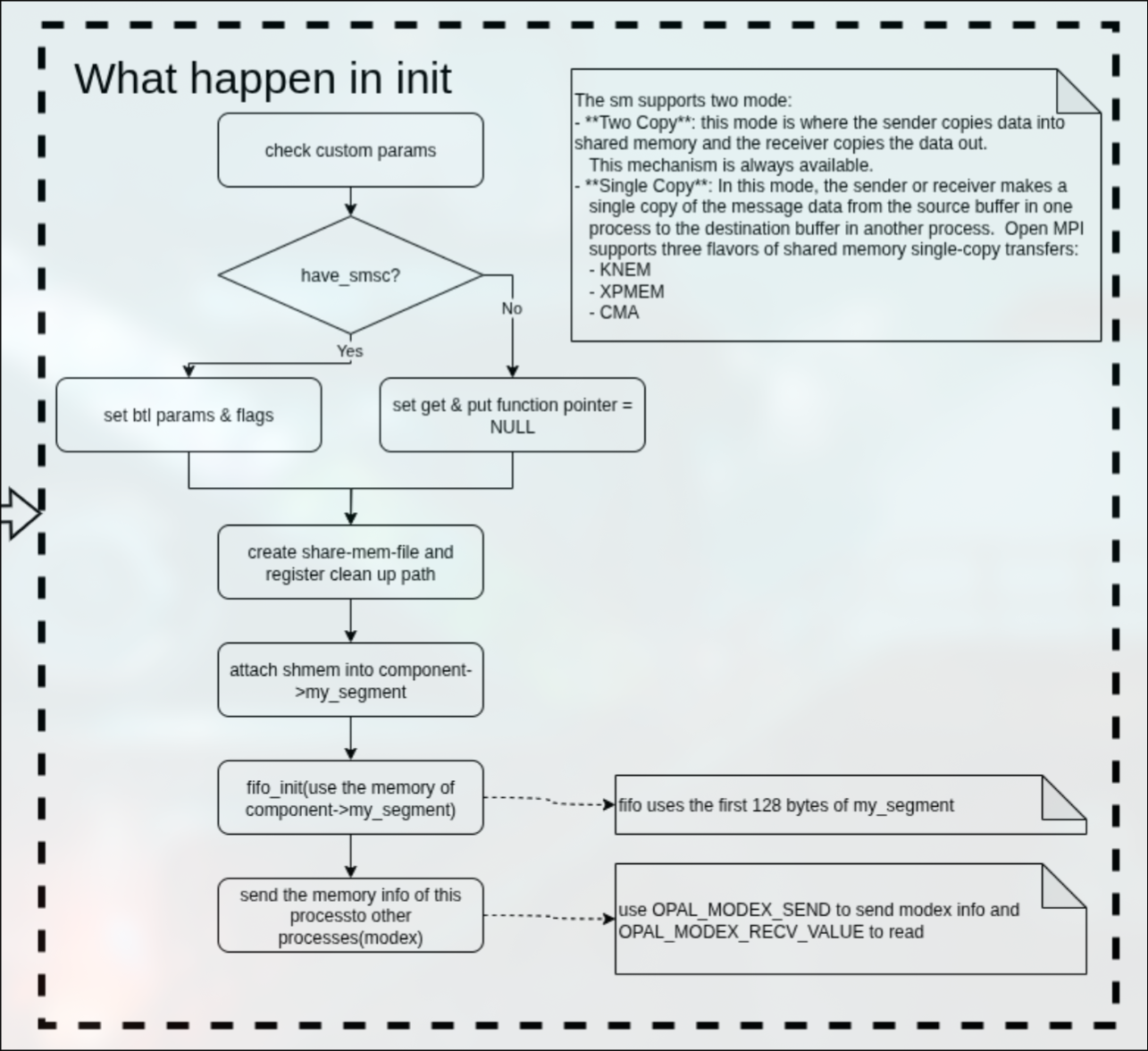
先检查用户所传递的自定义参数是否合法,之后判断是否具有SMSC。
SMSC是Linux实现的共享内存机制,可以跨进程共享数据,也是OMPI的sm组件里面实现single-copy的重要依赖。
如果支持SMSC的话就设置btl参数支持single-copy.
否则设置btl所需要的ops结构体中的rdma get/put为NULL,表示不支持rdma操作(必须通过openmpi buffer中转).
之后根据register中赋值的dir变量创建共享内存文件,并将共享内存文件attach到my_segment变量中,让这个变量指向这段共享内存。
在my_segment这段共享内存中,需要注意的是FIFO数据结构占据了前128个bytes.
最后通过MODEX操作发送这个memory info到对等进程中,告诉他们:嘿,我的内存在这个位置。
这里是否还记得之前的框图,btl/tcp组件有一个,但是有两个eth网口就有两个module.
这里如果通过sm进行通讯,则每一个进程就是一个module.
所以每个进程都有自己的共享内存区域。
具体框图如下:
add_procs
add_procs的过程是比self复杂很多的,因为设计到了ep(endpoint)的概念,此时内存不再是铁板一块,我们需要一种手段获取到对等进程的内存。
在add_procs中,会根据btl_inited变量来判断是否第一次初始化过,如果没有,就调用sm_btl_first_time_init()进行第一次初始化.
之后遍历所有进程,当进程的jobid与当前进程jobid相同并且属于local node的话,就会设置进程可见性。
在设置进程可见性后,通过init_sm_endpoint()初始化这个进程的ep.
具体框图如下:
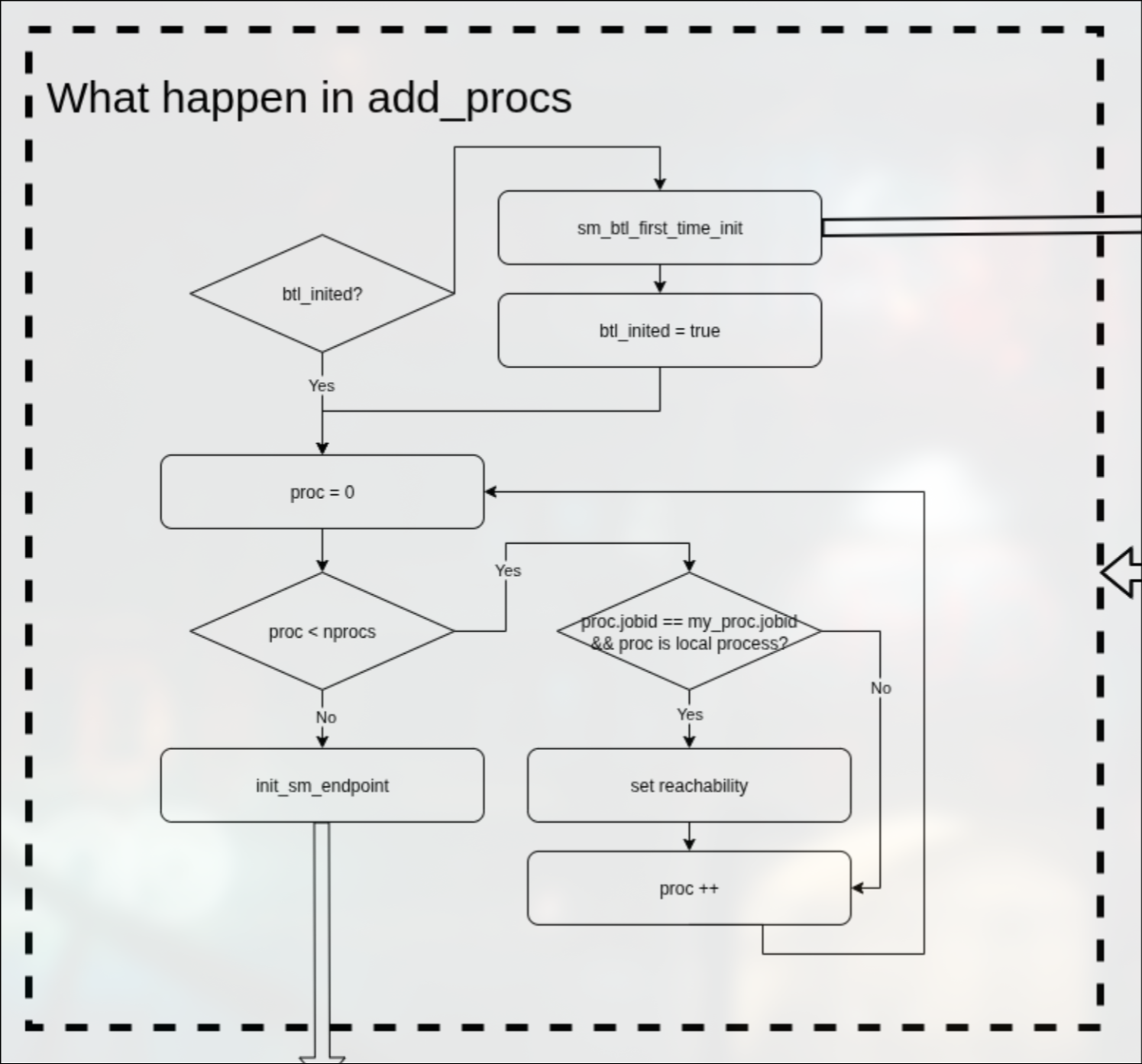
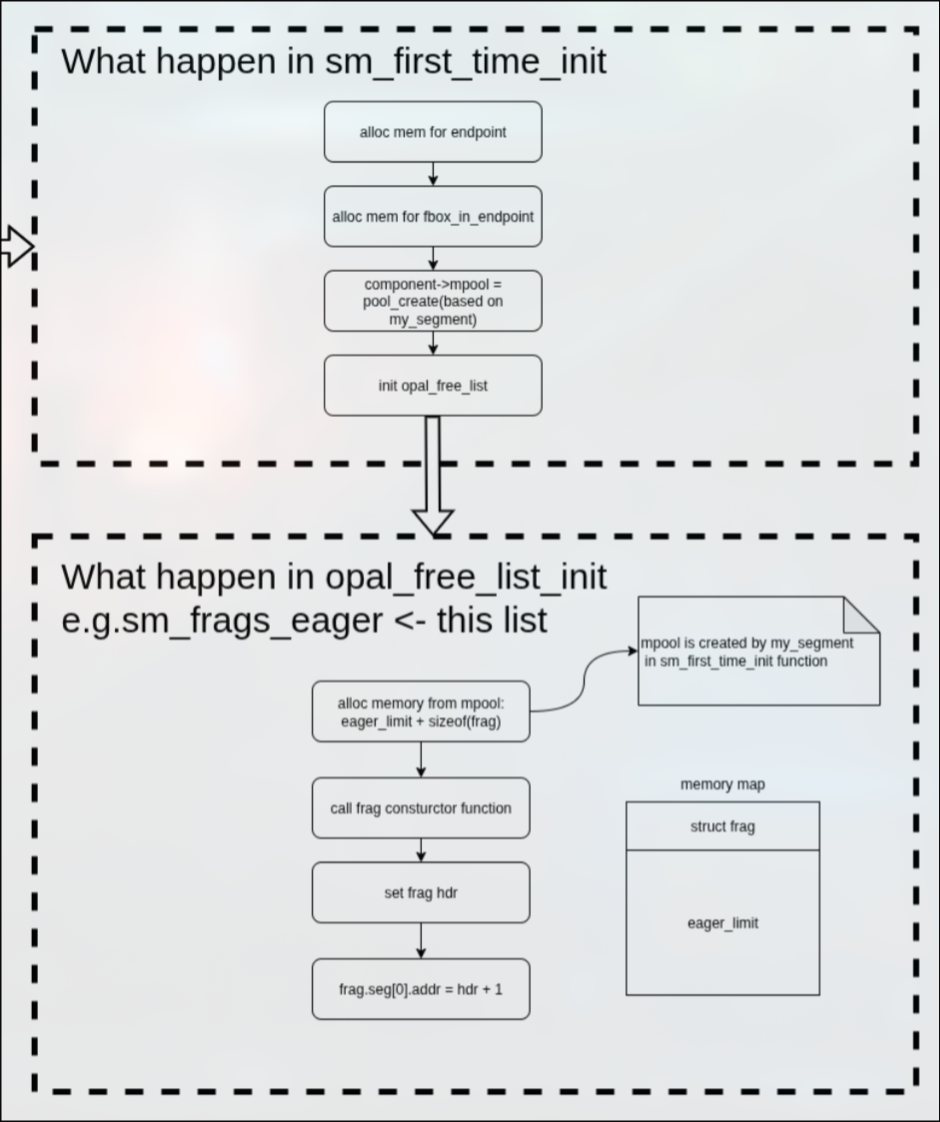
first_time_init
首先为endpoints数组动态分配内存(数组成员数量来自MCA_BTL_SM_NUM_LOCAL_PEERS),
之后给fbox_in_enpoints数组分配内存,数组成员数量如上。
之后创建内存池,内存池的内存空间由my_segment提供,my_segment变量在init的时候attach到了共享内存文件。
最后初始化free_list数据结构。
在初始化free_list的时候,流程与内存空间如下图所示:
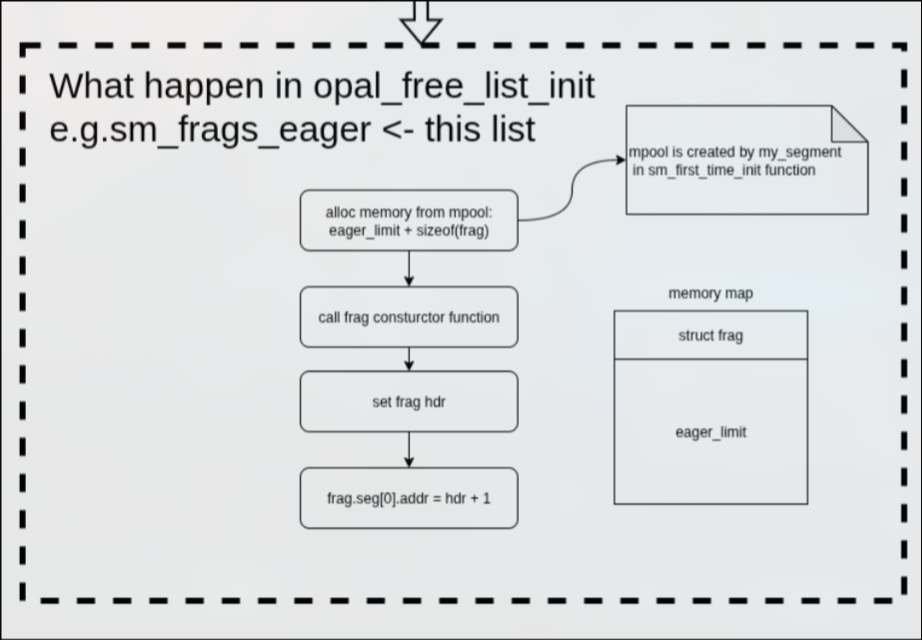
具体框图如下:
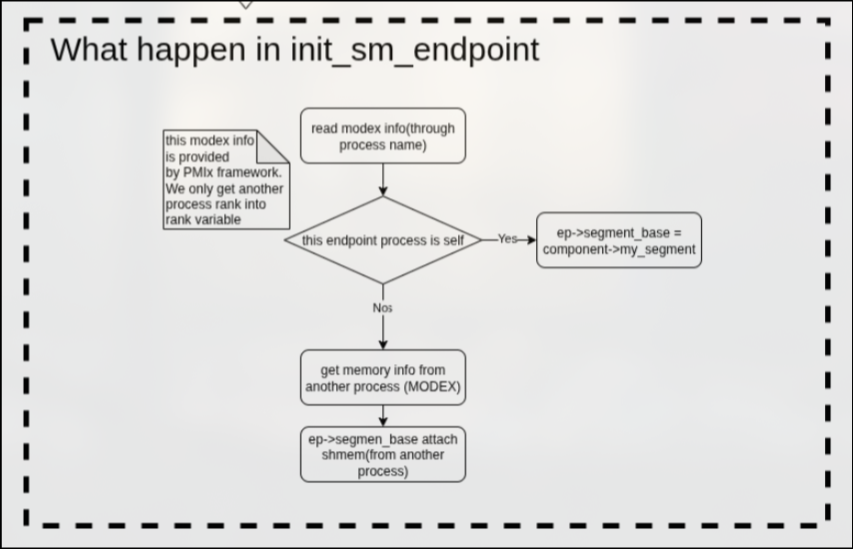
init_sm_endpoint
该函数会先通过modex拿到对等进程的信息,如果对等进程是本进程的话,那么ep->segment_base = my_segment;否则的话则通过modex拿到对等进程的内存信息,将ep->segment_base attach到对等进程的共享内存。
具体框图如下:
component完整框图
send
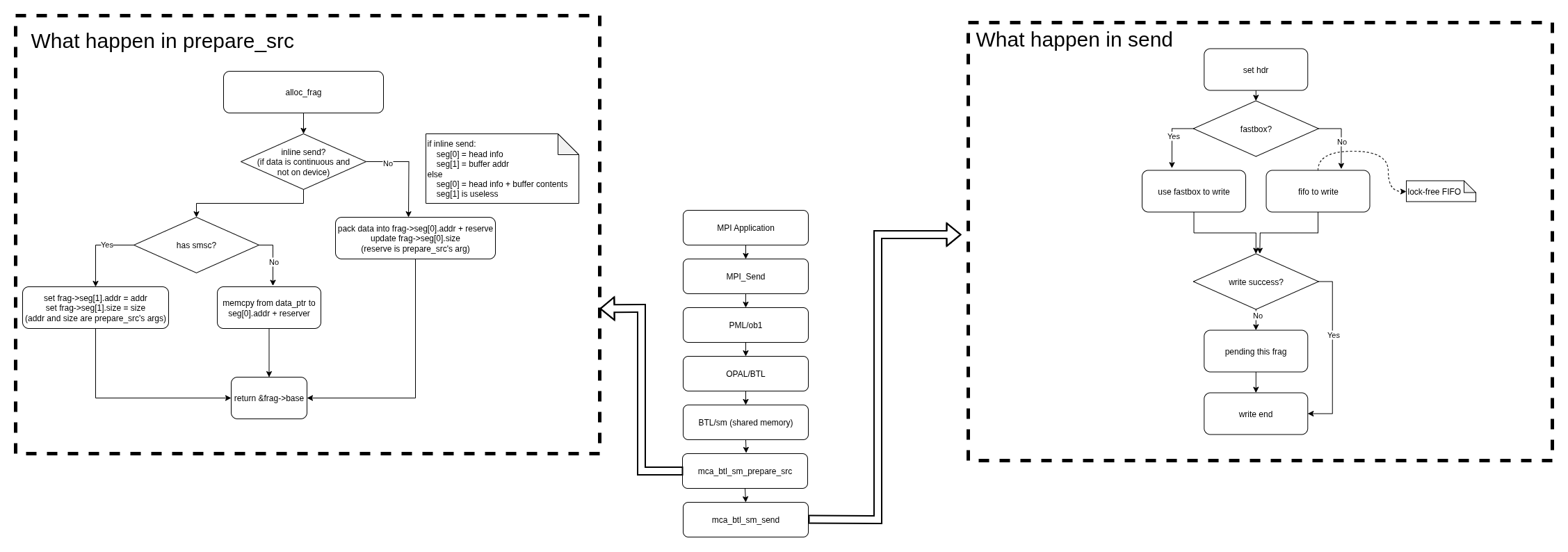
send的调用链与self相同,唯一不同的就是prepare_src和send函数的实现。
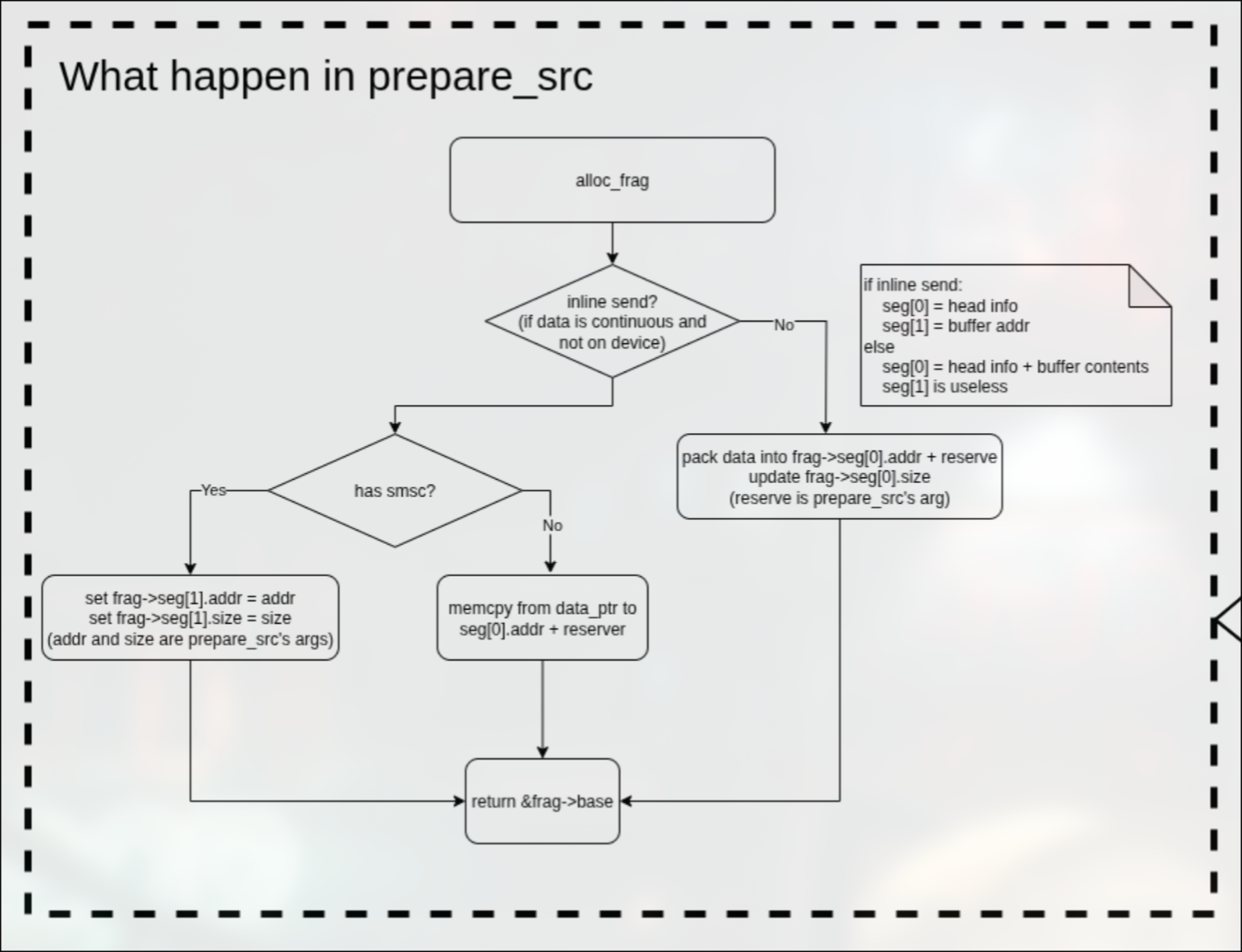
prepare_src
在prepare_src函数中,首先申请数据描述符。
在拿到数据描述符后,判断是否为内联发送(数据不在设备上并且是连续的内存空间)。
如果是内联发送,则判断是否具有SMSC(共享内存功能),如果有的话,则直接将地址写入数据描述符(single-copy);如果没有的话,则memcpy到到数据描述符中的预留空间。
如果不是内联发送,则通过covertor_pack函数将数据打包到数据描述符中的预留空间。
具体框图如下:
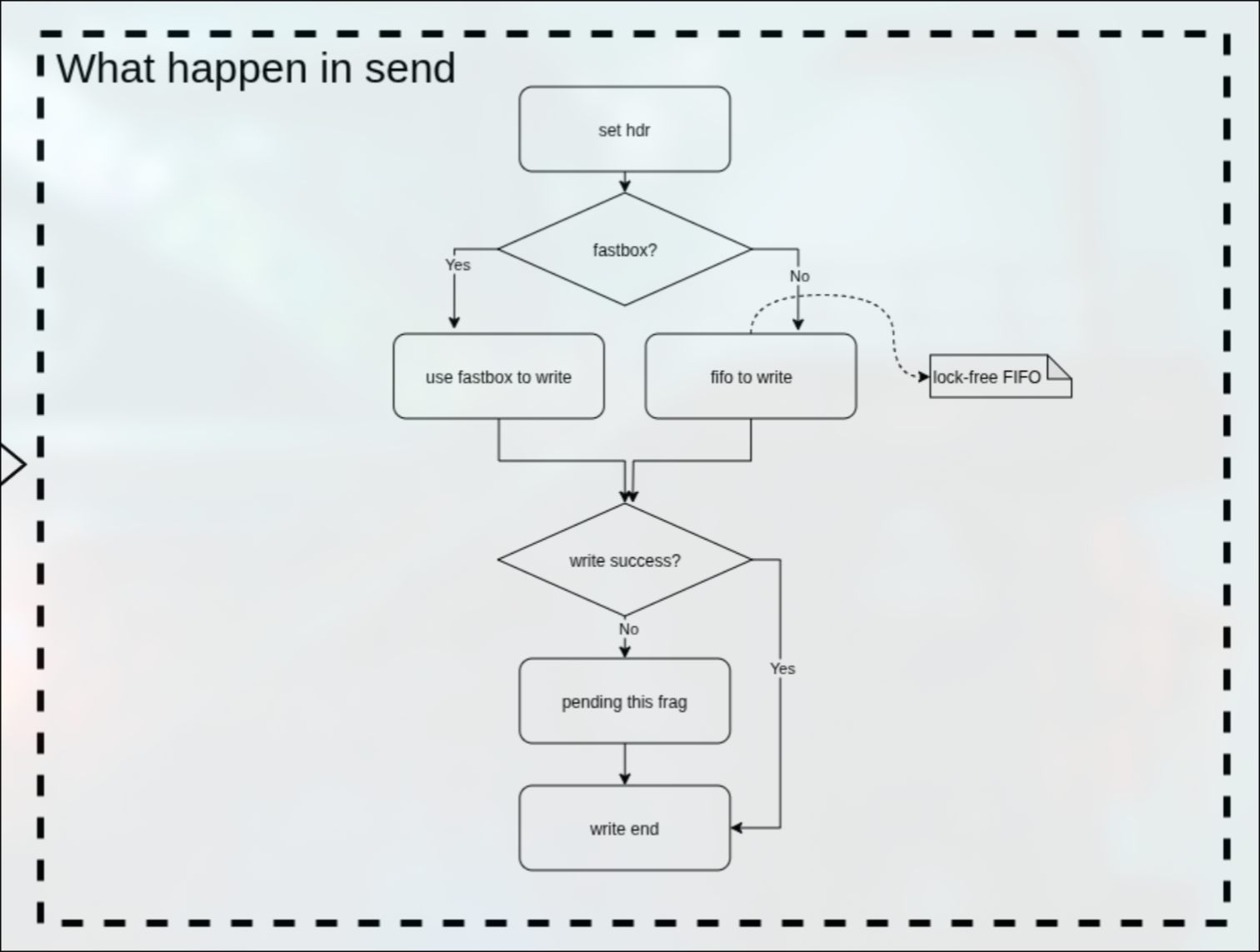
send
在send函数中,不能像self一样直接简单的调用openmpi内部的接收回调函数,需要实际发送。
首先设置hdr标志位,之后判断是否fastbox发送。
如果是fastbox发送,则直接通过fastbox发送。
如果不是fastbox发送,则通过sm实现的lock-free的FIFO进行发送。
之后判断是否发送成功,如果不成功,则将该数据描述符放到pending_list中。
等待合适的时机取出。
具体框图如下:
send完整框图
recv
recv的流程与self更是大相径庭,因为之前的self的recv只需要从ompi框架拿数据就可以了。
但是sm的recv需要来读取数据是否发送完成等操作,所以在component::ops里面引入了btl_progress()。
但是recv的调用链与self是相同的。
progress
在progress函数中,首先检查fastbox是否有数据需要处理,如果有,则处理.
之后检查是否有数据描述符挂到了pending_list中,如果有,则尝试将他们写入真正的FIFO中。
在这里再次失败了也没关系,失败的话就不会从pending_list中拿出,下次recv的时候依然会尝试再次写入。
在最后调用poll_fifo来检查fifo。
具体框图如下:
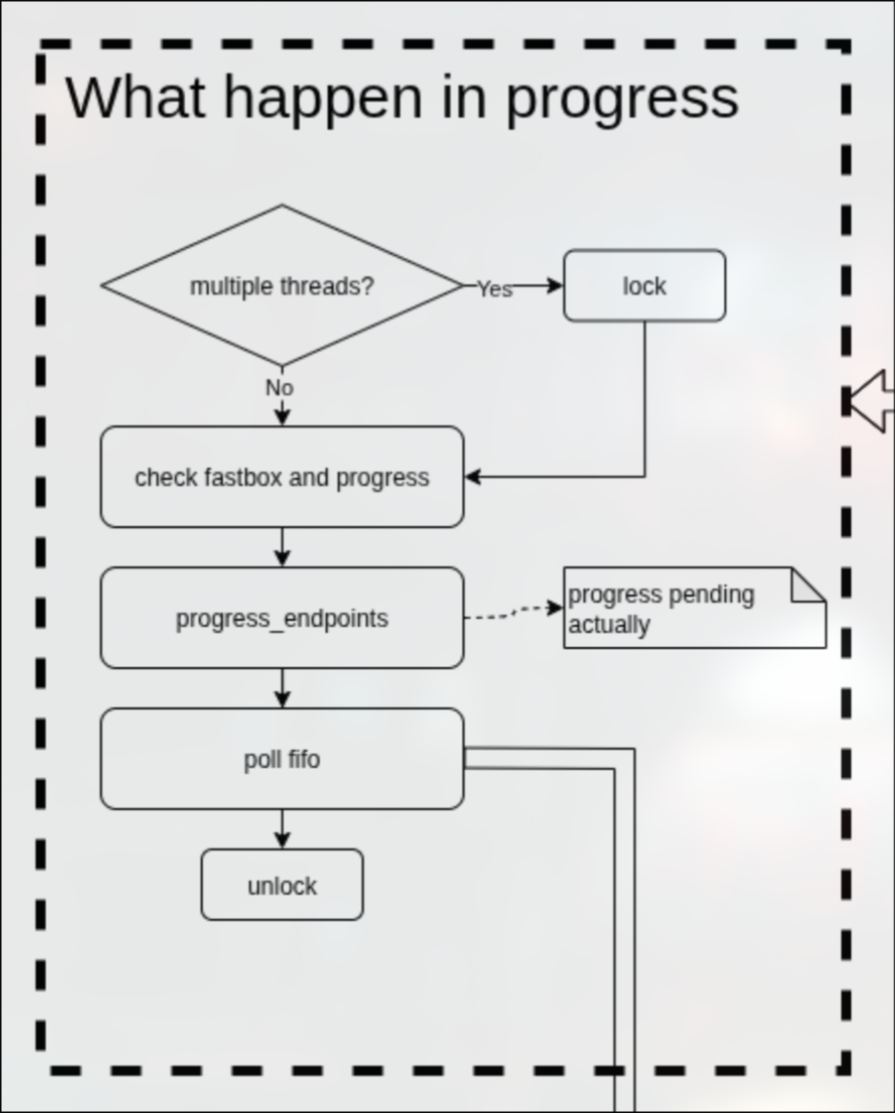
poll_fifo
在poll_fifo中,是一个31次的循环读fifo,这个值我并不清楚具体含义,可能是性能和效率的权衡。
在循环中,读取fifo,如果失败则返回。
如果读取fifo成功,则判断是否是一个已经完成的fifo,如果是的话调用数据描述符的回调函数。
如果不是已经完成的fifo,则判断是否为single-copy.
如果是single-copy,则映射endpoint的共享内存到本地。
如果不是,直接执行recv的回调函数。
之后将读取的这个fifo设置complete标志位,再回写到ep的fifo中。
具体框图如下:
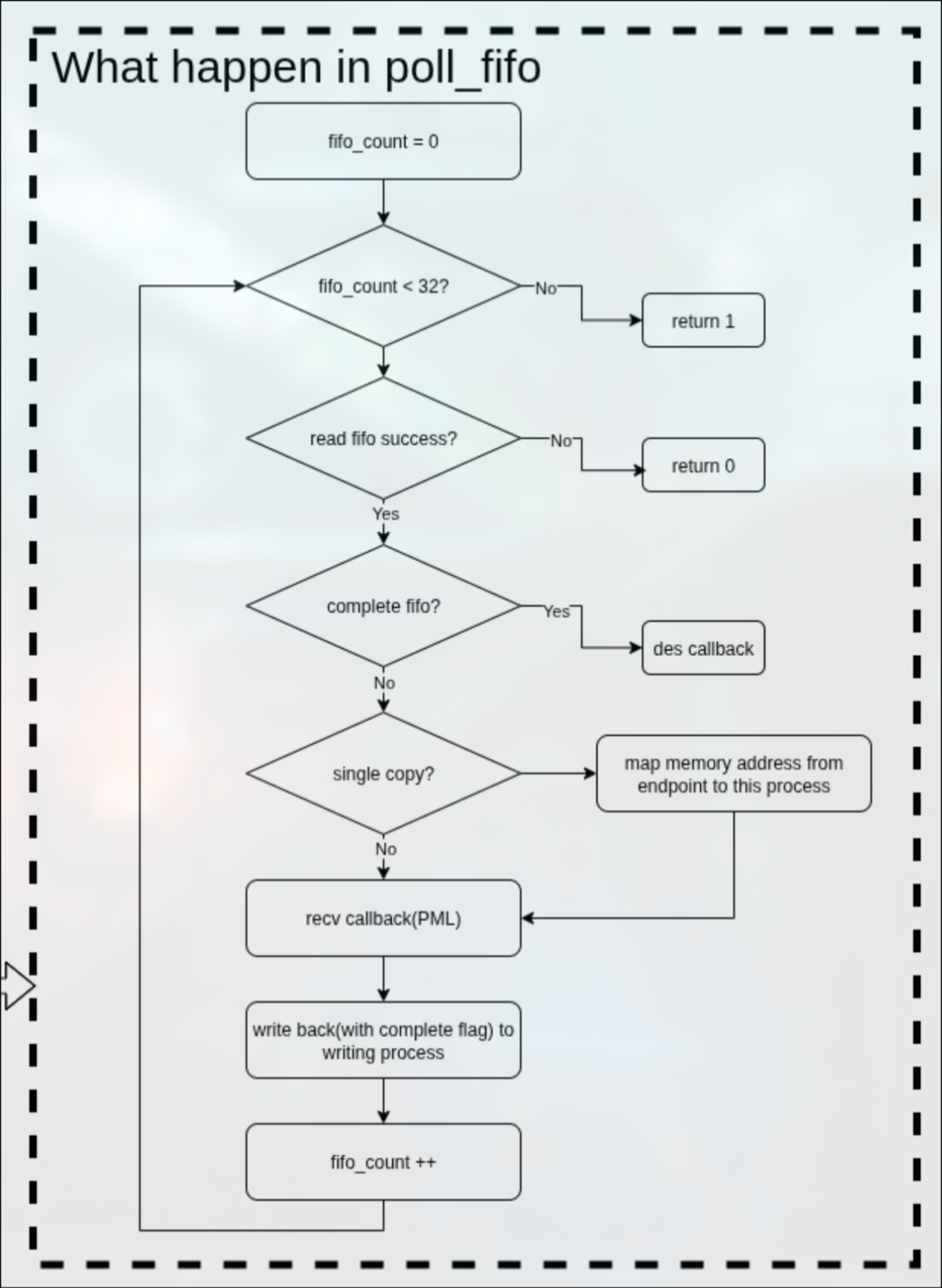
recv完整框图